

Duplicate content has raised questions for SEO experts for a long time. Is it the bête noire of SEO, to be avoided at all costs on pain of a site being removed from rankings altogether? What does Google really mean by duplicate content? By using information that has emerged over the last few years, including definitions provided by Google as well as tools and techniques, this article will provide you with greater insight into duplicate content.
What is duplicate content?
Google’s official definition of duplicate content, or content that is repeated on a website, is:
Duplicate content is generally understood to mean significant blocks of text that that are the same or very similar. These can be within a single domain or several domains, and can be identical or merely substantially similar.
This definition, provided by Google Search Console’s support, is so broad that it fuels theories and interpretations.
What are concrete examples of duplicate content, and how can it be distinguished from plagiarism?
Content produced on a website is considered to be duplicate when it is repeated several times online. This does not relate merely to a few words or phrases across multiple, different sites, but it does apply where the content in question copies significantly from another website or even the same website. The tolerance is set at a level of around 40% similarity. However, this duplication should be minimised wherever possible, and naturally external copies of entire blocks of text are to be avoided.
Here are a few examples given by Google that are considered to be duplicate content:
- Content copied and pasted from one site to another, such as quotations;
- Multiple URLs that point towards a single page, with Google treating them as two distinct pages;
- Title or meta description tags that are repeated throughout the site;
- Multiple identical versions of the website in existence under http or https connections, or with or without the www prefix;
And here are some examples of content that is not considered to be duplication:
- Items on sales sites that are online under multiple URLs (product files, e-commerce);
- Printable versions of web pages;
- Mobile pages that are distinct from their desktop equivalent.
It should be noted that Google clearly distinguishes between two different kinds of duplicate content, namely non-malicious content as described above, and content that is duplicated with the aim of cheating Google’s search algorithm to obtain a higher search ranking. These practices have more in common with plagiarism than mere repetition, and are illegal.
To remedy this point, Google will try to find the original source of the content and will prioritise the original content over pages that include duplicate content.
Following protocol – migrating from http to https and duplicate content
An error during the migration from http to https can result in the site being indexed twice (i.e., an indexation by different protocols). This specific case involves duplicated content as in the following example:
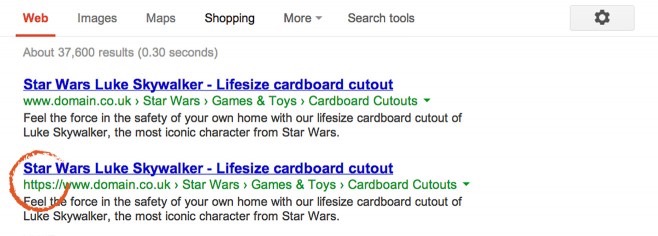
To ensure a successful transition from http to https, while avoiding duplicate content, you can follow our webinar on monitoring http/https migration with Myposeo (video).
Is publishing your own content from social networks or content platforms considered to be duplicate content?
We can refer to another case of duplicate content that is not listed directly in Google’s instructions. Indeed, webmasters wonder whether reposting content on Medium or LinkedIn Pulse after it has previously been published on their own website is considered to be duplicate content. We have already answered this question in a previous article on the Myposeo blog, and the answer is that it is generally not considered to be duplication provided that the source of the content is clearly and correctly identified.
How does duplicate content affect my SEO?
The myth of duplicate content
SEO experts have long considered that duplicate content causes Google to penalise sites or even remove them from their index altogether. Following the Google Panda update in February 2011, which was designed to combat content farms and low-quality websites, rumours of penalties were revived. Indeed, the new update penalised many websites and caused distress to webmasters all over the world, as it failed to distinguish between duplicate content and plagiarism.
Many questions were asked on discussion forums, wondering about who might be to blame for duplicate content on websites. The following example is taken from the Moz forum:
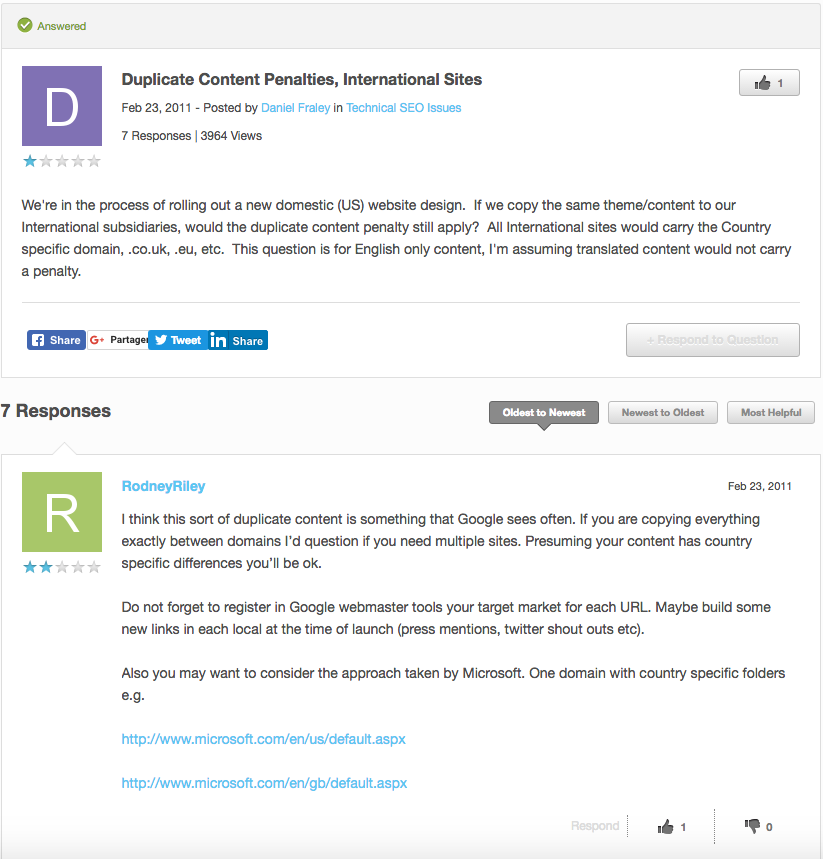
Question: we are moving forward with a migration to a US website. If we copy the same content and themes as our international subsidiary, will the duplicate content penalty still apply
Answer: I think that Google sees this kind of duplicate content quite frequently. If you copy between sites, I wonder whether you really need multiple sites…
A few years later, the question of penalties for duplicate content continues to occupy our minds. The following comment was found on a Kissmetrics article that dealt with myths around duplicate content:

Thanks for the comment Rick. The aim of the article was partly to discuss the myth of duplicate content but also to provide feedback from experience. If you see any examples of penalties, let me know!
The confusion even caused the Kern Media website to include duplicate content in its guide for avoiding penalties from the Google Panda update

So, what is the right answer? What do we know about the sanctions that duplicate content can trigger, via the official information provided by Google?
The reality of duplicate content
Susan Mowska has been attempting to silence rumours around the topic of duplicate content since September 2008. Indeed, the algorithm does actually deal with duplicate content by slowing down the indexation of websites that use it, but it does not impose any direct punishment, let alone leading to the site being removed from the index altogether.
In June 2016, Andrey Lipattsev, Search Quality Senior Strategist at Google Ireland, went even further in a Q&A session by specifying that the algorithm does not so much penalise sites that use duplicate content, so much as interpreting the content or adding a relevant content. He also specifies that the priority was to differentiate the user experience from that offered by Google’s competitors, and not to address duplicate content directly.
Here is the relevant Google Q&A session:
We now know that duplicate content is less serious than had been thought, although using it can still lead to a loss of ranking or a slowdown in Google’s indexation of the site. The algorithm is smart enough to distinguish between unique and duplicate content and to see if the content adds any value.
How to detect and remedy duplicate content?
It is legitimate to believe that all it is enough to prevent Google from crawling and indexing pages that include duplicate content by using a robot.txt file. However, Google advises against this practice in this specific instance, and recommends the following techniques instead:
Being careful with your content, and limiting repetition
This technique seems to be the most obvious, but it bears repeating. It is, therefore, important to ensure that you don’t copy and paste from one website to another and ensure that you always produce fresh content or at least content that is unique to our website. Google recommends that you don’t write for the search engine, but for visitors to the website directly. This simple piece of advice would prevent plenty of cases of duplicate content and should be followed before even beginning to address the more technical aspects of SEO.
Using 301 redirects
When Google indexes links to pages of duplicate content from a single site, the use of server-side redirects with the 301 response code is recommended. These redirects should be put in place from the duplicate page to the primary page and, as such, the crawler will know which page to index and rank highest.
URL canonicalization
The use of canonical URLs makes it possible to show a reference page to the search engine for indexing when one or more pages of a site feature duplicate content. As such, Google will not choose which page to index for itself, and will not, therefore, consider similar pages to be duplicate content.
To use a canonical URL, the canonical status must be given in the header, in the <head> part of the reference page and in the pages containing similar content:
<link rel= « canonical » href= « http://site.fr/url-de-references.html »/>
Specifying that the crawler should not index a particular page on the website:
<meta name=”robot” content=”Noindex, Follow”>
We use this tag to specify to Google that we do not want this page to be indexed, but that we do want Google to explore it nevertheless. It is important to let the robot crawl and read pages of duplicate content because concealing it can lead to penalties in terms of the search engine ranking.
This piece of code must be added in the <head> section of the relevant page, and it is ideal for different pages with a continuous layout.
Managing your site correctly using Search Console
By using Search Console, you can specify your favourite domain in the setting (i.e., with or without the www prefix). Choosing which (sub)domain Google should index makes it easier to avoid content duplication caused by a duplicate indexation of the site due to Google crawling both www.example.com and example.com. The parameter should be set as follows:
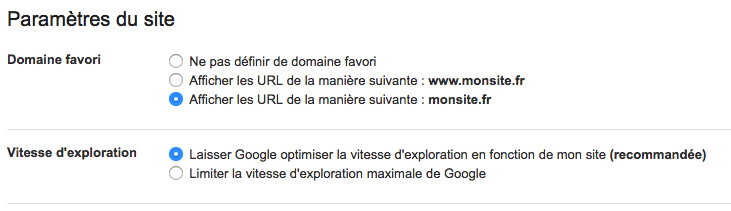
It is also possible to guide the Google bot by providing URL settings for it to interpret. If content such as legal notices is repeated on multiple sites, you merely create a link to a more detailed page and specify this in the Search Console. A user guide covering URL settings is available here.
Tools for checking, finding, and preventing duplicate content
Kill Duplicate is a tool that makes it possible to detect pages that plagiarise your site and to content the owners of those sites. If the dialogue does not result in a successful conclusion, an option enables you to contact the host of the site who can take action against this plagiarism.
The MOZ bar is a search engine plugin that enables the identification of title and meta description tags as well as the canonical URLs used on pages that you visit.
Sources :
Support Google Webmasters, https://www.hobo-web.co.uk/duplicate-content-problems/
Https://support.google.com/webmasters/answer/6080548?visit_id=1-636385707940773723-2205780584&rd=2
https://support.google.com/webmasters/answer/93633
Carol-Ann
Marketing manager @myposeo, community manager and writer.
- More Posts (664)